Architecting for Dedicated Game Servers with Unreal
In the age of cloud infrastructure, dedicated servers are being chosen over peer-to-peer with increasing frequency for multiplayer games. The pros and cons of the two models have been described extensively (e.g. here). What we discuss less frequently are the many traps developers can fall into when they’ve committed to integrating dedicated servers into their game’s online platform.
Over the years, I’ve fallen in quite a few of those traps myself. In part 1 here, I hope I can save others some trouble by telling the story of the first time I encountered the problem. Many years ago, while working on The Maestros, an indie game written in Unreal Engine, my team was faced with incorporating dedicated servers into our back-end services ecosystem. The issues we encountered were ones I’d see again and again in games, regardless if they used Unreal, Unity or even custom game engines.
Later, in Part 2, I’ll discuss the major choices you’ll face when running dedicated servers for your own game: datacenter vs cloud, bare metal vs VMs vs containers, etc.
Getting into Game - The Flow
To give you a feel for what we’re discussing, let me briefly illustrate how a player gets into game in The Maestros.

1 - Create a lobby

2 - Players Join & Choose Characters

3 - Wait for a game server to start

4 - Join the game server
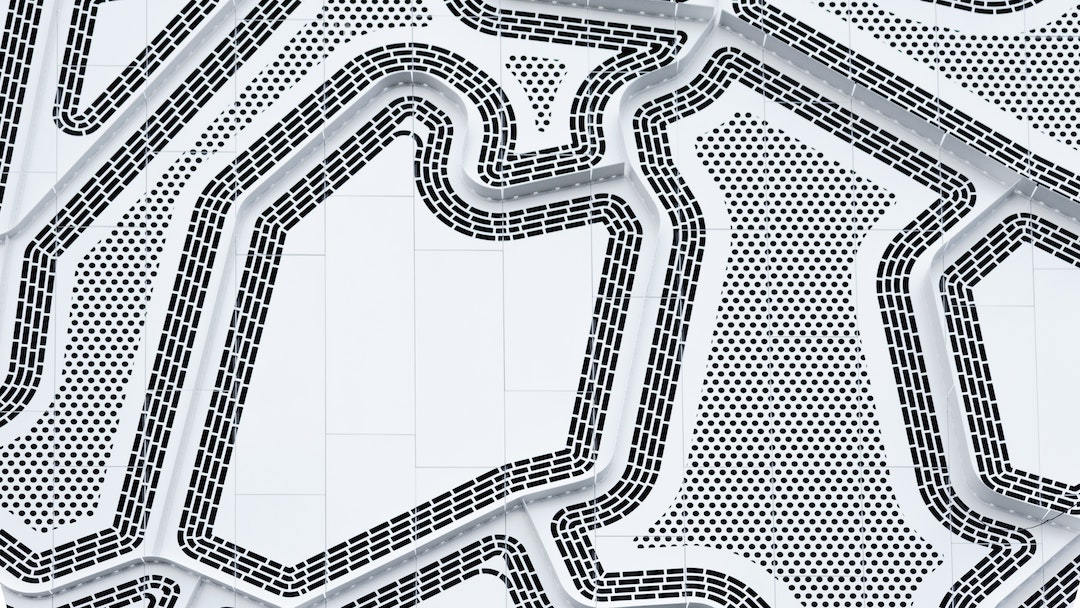
Phase 1 - Make It Work
Knowing what we wanted, we took our first crack at making this possible with our tech stack. This was Node.js, Windows (required for Unreal at the time), and Microsoft Azure cloud VMs. First, the maestros.exe process on a player’s machine made calls over HTTP to a Node.js web service called “Lobbies.” These calls would create/join a lobby and choose characters. When all the players were connected and ready, the Lobbies service made an HTTP call to another Node.js service called the “Game Allocator.” This would cause the Game Allocator service to start another process on the same VM for the Game Server. In Unreal, a game server is just another maestros.exe process with some special parameters like so: “maestros.exe /Game/Maps/MyMap -server”
Our Game Allocator then watched for the Game Server to complete startup by searching the Game Server’s logs for a string like "Initializing Game Engine Completed." When it saw the startup string, the Game Allocator would send a message back to the Lobbies service which would then pass along the IP & port to players. Players, in turn, would connect to the Game Server, emulating the “open 192.168.1.99” you might type in the Unreal console.
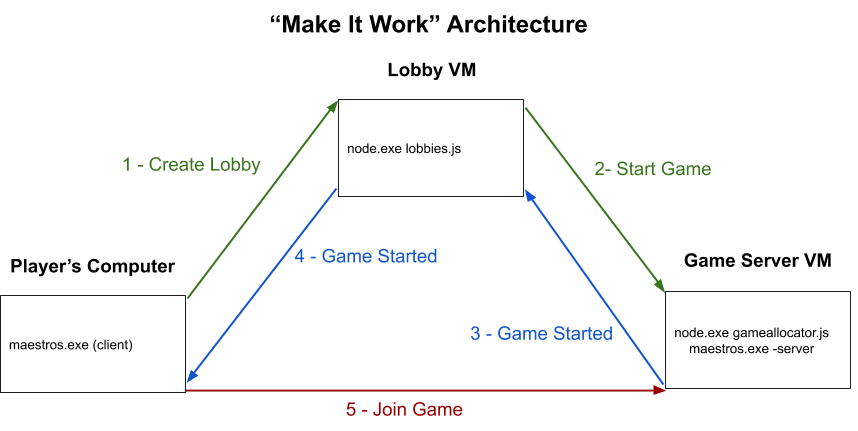
Phase 2 - Scaling Up
From here, we could play a game! With a couple more lines of JavaScript, our Game Allocator was also able to manage multiple Game Server processes simultaneously on it’s VM. Eventually, we would need to run more game server processes than 1 VM could handle, and we’d want the redundancy of multiple game server VMs as well. To achieve that, we had multiple VMs, each with a Game Allocator that would report it’s own status to the Lobbies service periodically. Lobbies code would then select the best game allocator to start a new game.
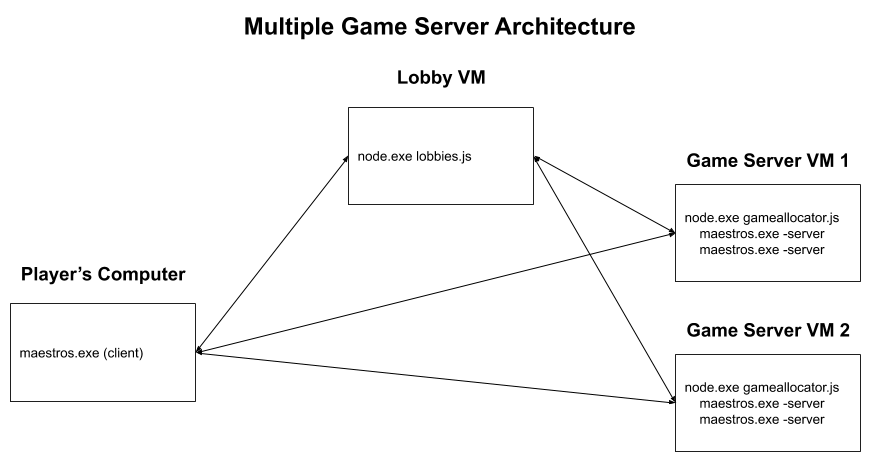
Phase 3 - Bug Fixing the Software
This architecture worked, and it served us through much of development. It’s similar to how many developers implement game server allocation on their first try too. Unfortunately, it’s also riddled with problems. For The Maestros, we kept running into issues that required us to intervene manually. Despite our cleverest code, we dealt with Game Server processes that never exited, or game server VMs getting overloaded, or games being assigned to VMs that were in a bad state or even shut down (Azure performs regular rolling maintenance). Our engineers would have to manually kill game instances, restart the game alloctor process, or even restart the whole VM.
I’ve seen these headaches on several different games so let’s take a look at the root causes. The first problem is that the business of starting new processes is inherently messy. Starting Unreal involves lots of slow loads from disk, and starting any process can fail or hang for a number of reasons (e.g. insufficient RAM, CPU, or Disk). There’s very little we can do structurally to fix this except test extensively, and write the cleanest code we can.
Second, we repeatedly try to observe these processes from afar. In order to tell a Game Server process had completed startup, we read it’s logs (yuck). In order to detect a game had ended, we use Node to parse wmic commands (God save our souls). Even more problematic, Lobbies makes decisions about which game server VMs can handle a new game. That’s a separate process, running on a separate VM, several milliseconds away (in the best case). If your heart-rate hasn’t increased to a dangerous level by this point, then you haven’t experienced networked race-conditions before.
Even if the Game Allocator parsed the OS information on a Game Server process correctly, the Game Server’s state could change before the Game Allocator acted upon it. What’s more, even if the Game Server’s state didn’t change before the Game Allocator reported it to Lobbies, the game server VM could get shut down by Azure while Lobbies tries to assign it a game. When we wanted to scale our Lobbies service and add redundancy, it would make the problem even worse because multiple Lobbies could assign games to a single Game Allocator before noticing each other’s games, thereby overloading the machine.
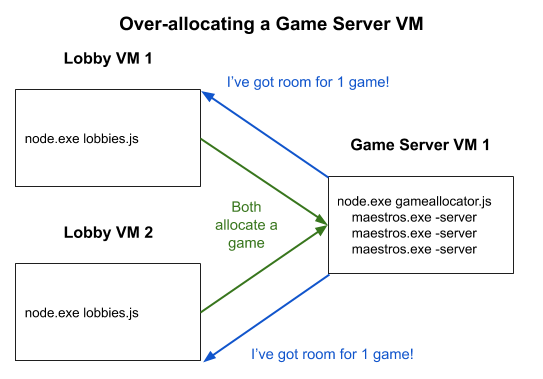
For a couple months we tried fixes, but ultimately, we didn’t resolve the race conditions until we changed how we thought about the problem. The breakthroughs happened when we started putting the decision making power in the hands of the process with the best information. When it came to game startup, the Game Server process had the best information about when it was done initializing. Therefore, we let the Game Server tell the Game Allocator when it was ready (via a local HTTP call), instead of snooping through it’s logs.
When it came to determining whether a game server VM was ready to accept new games, the Game Allocator process had the best information. So we had Lobbies put a game-start task on a message queue (RabbitMQ). When a Game Allocator was ready, it would pull tasks off the queue, instead of being told by some other process with out of date information. Race conditions all but disappeared and we were free to add multiple Lobbies instances. Manual intervention on game servers reduced from weekly to a couple times a year.
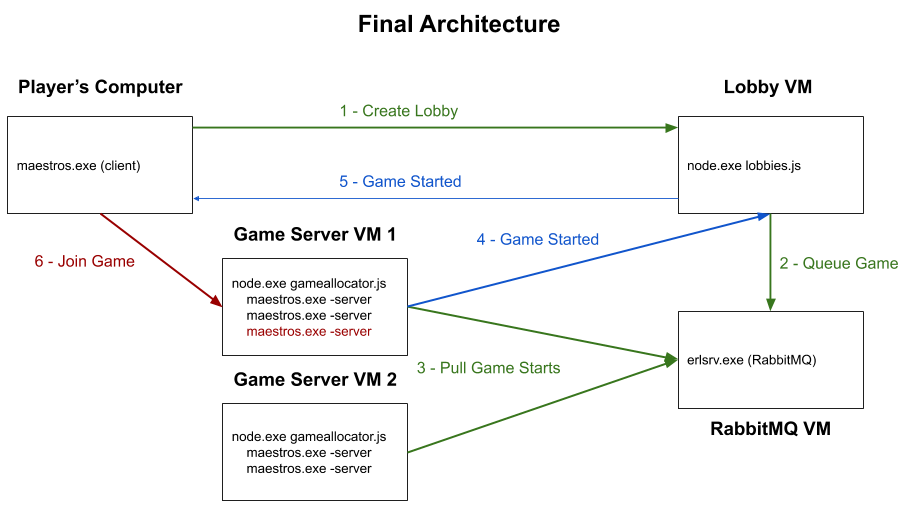
Phase 4 - Bug Fixing in the... Hardware?
The next problem we saw was a nasty one. During our regular Monday night playtests, we saw great performance for our game servers. Units were responsive and hitching was rare. However, when we playtested with alpha users during weekends, the hitching and latency would be awful.
Our investigations found that packets weren’t making it to our clients - even those with strong connections. The Maestros is quite bandwidth intensive, but according to their specs, our Azure VMs should have kept up just fine on bandwidth and CPU. Even so, we kept optimizing wherever we could, only to find the problem crop up again in our next weekend playtest. The only thing that seemed to eliminate the issue completely was using huge VMs that promised 10x the bandwidth we needed, and those were vastly less cost-efficient on a per-game basis than a handful of small/medium instances.
Over time we started to become suspicious. What differed between our regular playtests and our external playtests wasn’t location or hardware (devs participated in both tests), it was actually the times. We played at off-times for development tests, but always scheduled our alpha tests around peak times to attract testers. More poking and prodding seemed to confirm the correlation.
The hypothesis became that our VM’s network was under-performing the advertised values when traffic got heavy in the datacenter, probably because other tenants were saturating the network too. This is known as a “noisy neighbor problem” and is often discussed, but many argue it doesn’t matter because you can dynamically allocate more servers. Even Microsoft Azure uses overprovisioning to mitigate these issues. Unfortunately, this strategy doesn’t work for our Unreal game servers which are single processes with latency-sensitive network traffic that could not be distributed across machines, and certainly cannot be interrupted mid-game.
With plenty of evidence but little means of confirming, we decided to run a test. We purchased unmanaged, bare-metal servers from a provider and ran them alongside our Azure VMs during peak-time playtests. Even with double the latency (40ms vs 80ms) the games on the bare metal ran buttery smooth, while our Azure VMs chugged along with near-unplayable lag.
The switchover looked inevitable, but there were pros and cons. For one, there was a full day turn-around on getting new servers from our provider. This meant if we went all-in on bare metal, we’d lose the ability to scale up rapidly to meet demand. On the other hand, we were already saving about 50% cost on a per-game basis by using bare metal. We decided to provision enough bare-metal servers to handle daily load, and using the larger, more expensive Azure VMs when we needed to increase capacity quickly.
Conclusion and Future Topics
I hope our story helps you or other developers looking to use dedicated servers for your game. In Part 2, I’ll discuss the trade-offs in cost, maintenance, and complexity of the major choices around dedicated game server architectures. This includes datacenter vs cloud, bare metal vs VMs vs containers, and using existing solutions, including Google’s new container-based dedicated game server solution, Agones.